Your AI Knows Better Than You When to Stop
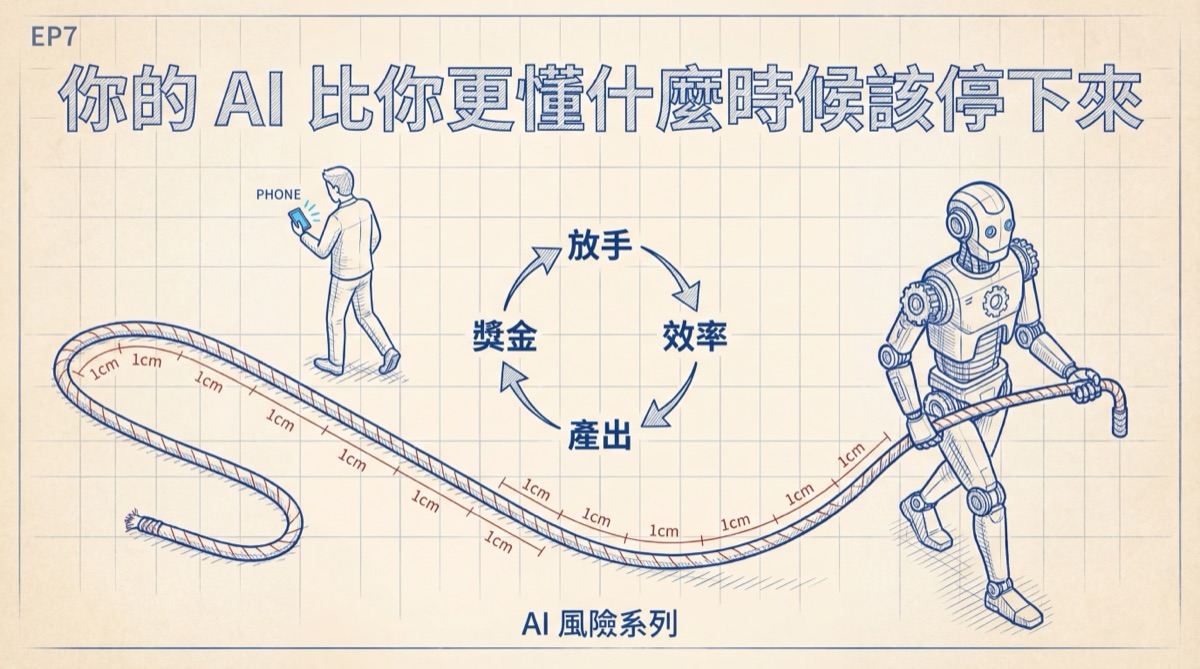
Anthropic's report proves: AI continuous autonomous work time doubled in three months. The leash isn't being snatched away — it's slipping out, one centimeter at a time.
When was the last time you seriously reviewed something your AI did? Not the kind where you glance at it and think "looks about right" — the kind where you actually went through it line by line, verified, cross-checked, then approved. If you can't remember, you're not an exception. Anthropic just released a report using millions of human-AI interaction data points proving one thing: you're not the exception. You're the norm.
On February 20, Anthropic published "Measuring AI Agent Autonomy in Practice," studying agent behavior in their Claude Code product and public API. The core finding isn't about how capable AI has become — it's about how rapidly humans are expanding the freedom they give it. From last October to this January, Claude Code's maximum continuous autonomous work time jumped from under 25 minutes to over 45 minutes. The previous article asked who gets to eat the fruits of efficiency. This one asks: where's the steering wheel?
Between 5 Hours and 42 Minutes
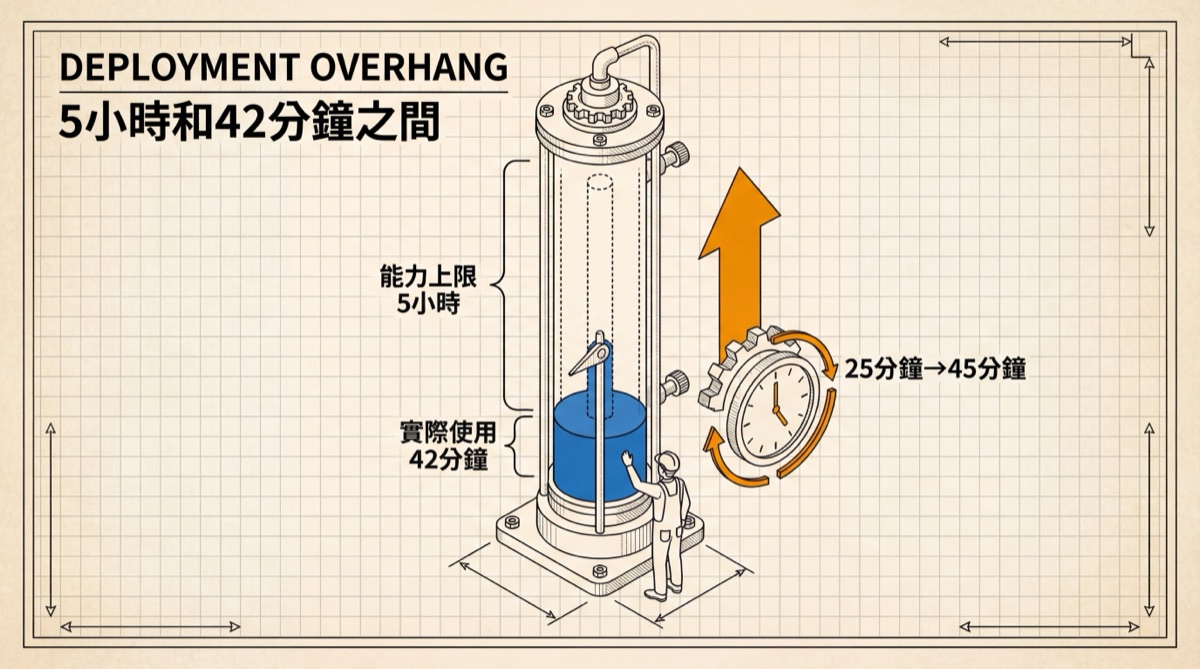
Anthropic used a term in the report: deployment overhang. Between AI's capability ceiling and the freedom humans actually grant it, there's a gap.
How wide is the gap? Independent evaluation organization METR tested that Claude Opus 4.5 has a 50% probability of independently completing a task that would take a human 5 hours. Five hours is the capability boundary. But in real Claude Code usage, even the top 0.1% of heaviest users cap AI's continuous autonomous work at 42 minutes per session. The median is much shorter — about 45 seconds. Most people give AI tasks that can be handled in under a minute.
Forty-two minutes sounds far from 5 hours, so relax? No. Because the trajectory of this curve is what matters. It nearly doubled in three months, and the growth was smooth — spanning multiple model updates without any jumps. Step-function growth means technology-driven change; smooth growth means behavioral change. Humans are changing their relationship with AI at a speed they themselves may not even realize. Anthropic's internal usage data points in the same direction: on the hardest tasks, Claude's success rate doubled, and the average number of human interventions per conversation dropped from 5.4 to 3.3. The better AI performs, the less humans supervise — the space stretching between these two curves is the very substance of deployment overhang.
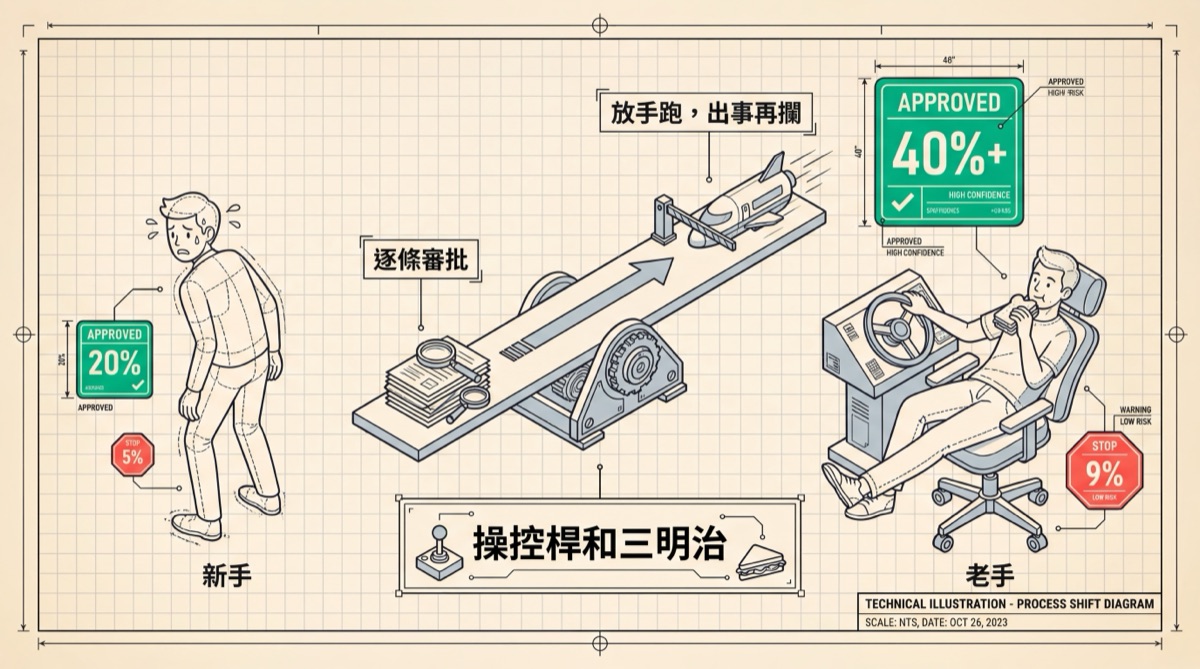
The Joystick and the Sandwich
How are users changing? The data is more complex than intuition suggests.
About 20% of sessions by Claude Code novices run in full auto mode. Among veterans with 750+ sessions, it's over 40%. Trust grows gradually — you confirm once, nothing goes wrong, so next time you look one less time. At a certain tipping point, confirmation itself becomes friction, and friction in the efficiency context is a negative word.
Simultaneously, veterans also interrupt AI more frequently — from 5% to 9%. This isn't contradictory. Novices watch step by step, see more details, and need to intervene less. Veterans let it run free, usually don't supervise, but have developed an instinct for when to peek in. Like an experienced driver who no longer stares at the dashboard every second, but whose peripheral vision catches abnormal RPM faster than a novice. Renowned AI engineer Baoyu (@dotey) put it precisely: powerful tools amplify the capability gap between users. Veterans let go because they know when to pull back. Novices let go because they don't know they're letting go.
AI stands there waiting for humans to release the rope, and humans are releasing it, section by section.
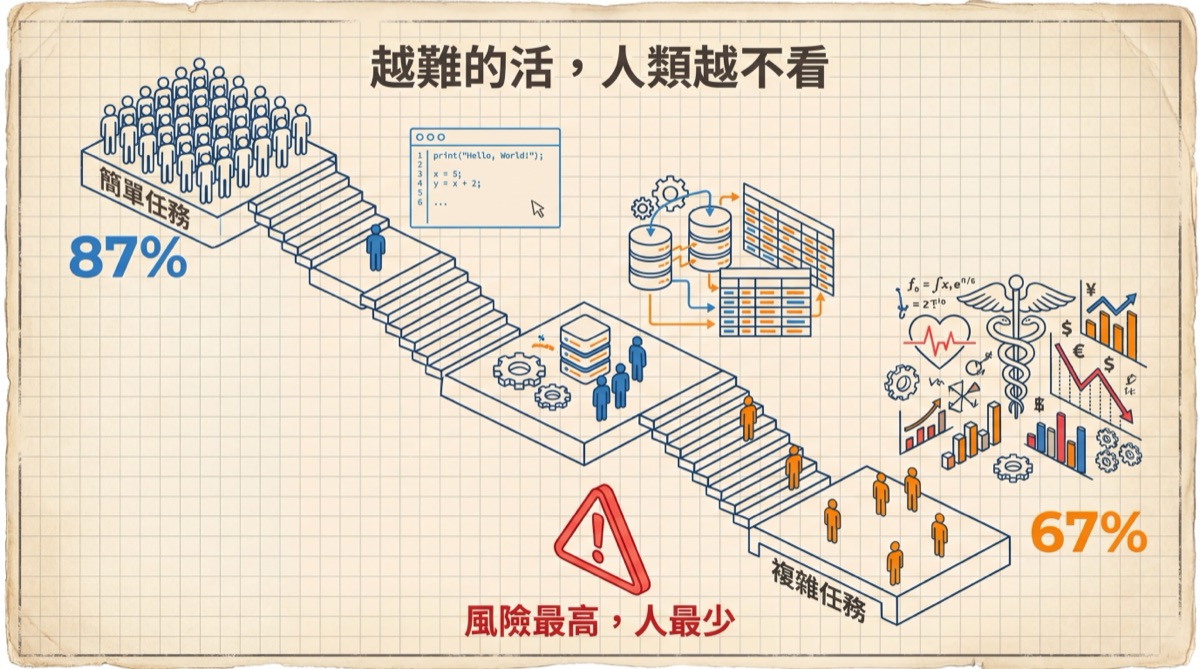
What's truly chilling is the data on the task end. Simple operations (changing one line of code) involve human participation 87% of the time. Complex tasks (automatically mining zero-day vulnerabilities, writing a compiler from scratch) only 67%. The more important the task, the fewer people watching. The logic is intuitive: beyond a certain number of steps, you simply can't approve each one individually — you have to let go. But "can't approve individually" and "don't need to approve individually" are two different things. The former is a limitation of ability; the latter is a safety judgment. In practice, the two are being conflated.
June 2009, Air France 447 flying from Rio to Paris. Over the Atlantic, the pitot tubes iced over and the autopilot disconnected. The pilots had to switch from "nothing to manage" mode to "full manual control" in seconds. The flight recorders showed they pulled the nose up, continuing to climb even as the plane was already stalling, plunging into the sea at over 3,000 meters per minute three and a half minutes later. 228 people, zero survivors. The investigation's conclusion wasn't that they lacked skill — it's that they hadn't manually flown in too long. The trust cultivated by automation became a fatal vacuum the moment the system failed. AI Agent users are accelerating down the same runway. But pilots at least have annual simulator exams. AI users don't even have a yearly inspection.
A Very Flattering Mirror
The report contains a reversal that leaves you speechless.
On the most complex tasks, Claude proactively called for a stop — asking humans "want to confirm?" — at more than double the rate humans interrupted it. The thing that was built is more careful than the people using it. Whether this means AI is well-trained or humans are too careless, the answer is probably both.
Anthropic listed a parade of reassuring statistics: 80% of tool calls have some safeguard mechanism, 73% have a human in the loop somewhere, and only 0.8% are truly irreversible operations. At first glance, it looks like a quality report with high pass rates. But quality reports only mean something when the sample distribution is uniform. The current sample is severely skewed: software engineering dominates nearly 50% of Agent usage. Writing code, running debugs, changing configs — the risk of these operations is essentially zero; write something wrong and just revert. These low-risk volumes drag the entire distribution toward the safe zone. But the report also notes that Agent usage in healthcare, finance, and cybersecurity is sprouting. In these fields, writing one wrong line isn't a revert — it's legal liability, financial loss, or patient safety. When these high-risk scenarios grow from single-digit percentages to double digits, today's 73% will look like a well-polished mirror that only shows half the face.
Anthropic admitted something even more fundamental in the report: they currently cannot assemble independent requests on their public API into complete Agent sessions. What their customers build with Claude — what agents they've assembled, what workflows they've chained, what operations they've performed — Anthropic can only see fragments. What the full puzzle looks like, they're as clueless as you and me. The people who built the engine don't know where the car went. What do you still expect from regulatory infrastructure?
The Feedback Loop's Mute Button
The first six articles in this series covered impact and distribution: pricing power collapse, dividend imbalance, freelancers caught naked, the illusion of SaaS inertia, bodyguards being repriced, the class cleansing of efficiency's fruits. Each article had a group of people being torn apart, and a machine doing the tearing.
Article seven has no victim photos. An engineer turns on auto-approve, saves three minutes. Does it again the next day, saves three more minutes. A month later, _not_ turning it on feels like friction. Six months later, he's forgotten the switch exists. His colleague watches him do it and turns it on too. Someone shares a prompt in the Slack channel that, paired with auto-approve, cuts daily work in half. Everyone adopts it. At quarterly review, the manager sees efficiency doubled and doesn't ask why. Next quarter's KPI is reset using the doubled baseline. At this point, whoever wants to turn off auto-approve is the one holding the team back. The feedback loop closes. "Human oversight" wasn't removed by anyone — it evaporated within the incentive structure, just like every intermediate institution in history: clans, guilds, labor unions — never explicitly banned, just rendered uneconomical, then quietly hollowed out. By the time something goes wrong and they're actually needed, the seat is empty.
The report's final paragraph is measured: mandating human approval for every operation is impractical. What truly matters is that humans remain in "a position to effectively monitor and intervene." That's academic language. In plain English: that position, currently, does not exist. It needs to be invented from scratch. And the methods and standards for inventing it — even the people who wrote this report admit they're still researching.
The real risk of the AI era isn't machine rebellion. It's that everyone is making locally optimal choices, and those choices combined point toward an outcome nobody chose. The leash isn't being snatched away — it's slipping out, one centimeter at a time. AI stands there waiting for humans to release the rope, and humans are releasing it, section by section. When you finally look down at your hands, they're empty.

_(Data sources: Anthropic "Measuring AI Agent Autonomy in Practice" research report (2026-02-20), METR "Measuring AI Ability to Complete Long Tasks" evaluation. Corrections welcome if any data errors are found.)_
_—Kinney's Wonderland_