你的 AI 比你更懂什麼時候該停下來
Anthropic 的報告證明:AI 連續自主工作時間三個月翻一倍。韁繩不是被搶走的,是一厘米一厘米滑出去的。
你最後一次認真審核 AI 替你做的事,是什麼時候?不是掃一眼覺得「差不多」,是真的逐行看過、確認過、對過才放行的那種。如果你想不起來,你不是特例。Anthropic 剛發了一份報告,用幾百萬筆人機互動數據證明了一件事:你不是特例,你是常態。
二月二十日,Anthropic 發佈了《Measuring AI Agent Autonomy in Practice》,研究他們自家的 Claude Code 和公共 API 裡的 Agent 行為。核心發現不在於 AI 變得多厲害,而在於人類給它的自由度正在快速膨脹。去年十月到今年一月,Claude Code 最長連續自主工作時間從不到25分鐘翻到超過45分鐘。上一篇寫的是效率的果實被誰拿走了。這一篇要問的是:方向盤呢?
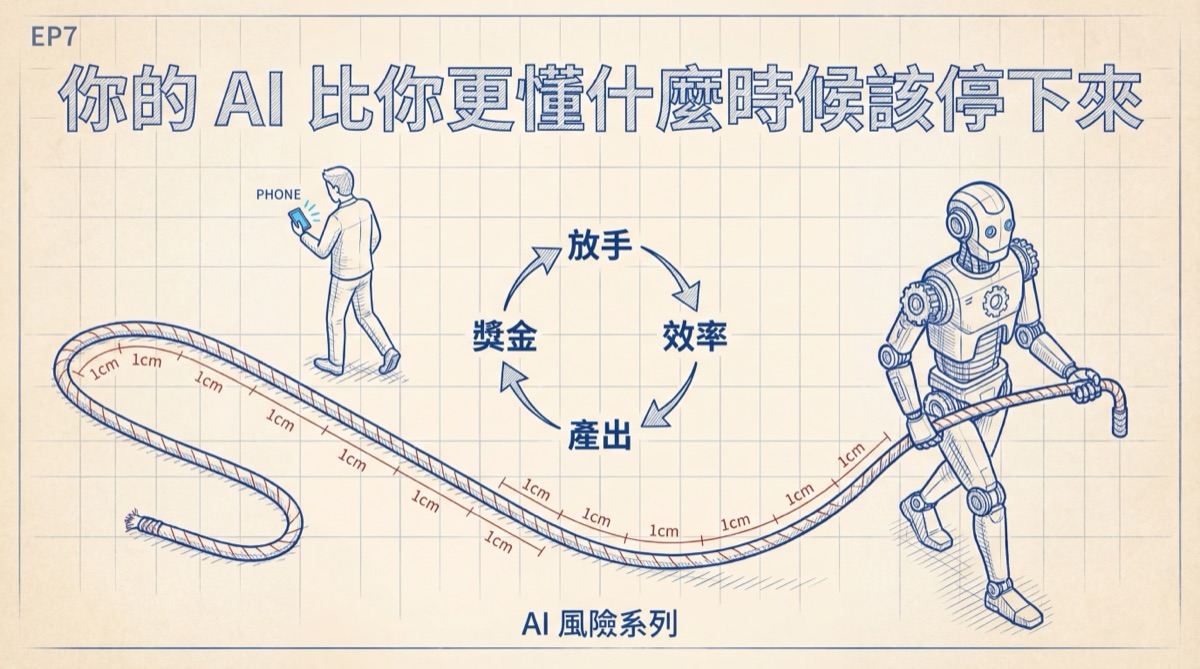
5小時和42分鐘之間
Anthropic 在報告裡用了一個詞:deployment overhang。AI 的能力天花板和人類實際放行的自由度之間,有一道裂縫。
裂縫有多寬?獨立評估機構 METR 做過測試,Claude Opus 4.5 有50%的機率能獨立完成一件人類需要花5個小時的任務。5小時是能力的邊界。但在 Claude Code 的真實使用裡,即使是使用最密集的前0.1%用戶,單次讓 AI 連續自主工作的時間上限也只有42分鐘。中位數更短,大約45秒。大多數人給 AI 的活,都是一分鐘以內能搞定的碎事。
42分鐘聽起來離5小時還很遠,所以放心?不。因為這條曲線的走向才是重點。三個月漲了將近一倍,而且漲勢是平滑的,跨了好幾次模型更新都沒有出現跳躍。階梯式的增長代表技術推動,平滑的上升代表行為改變。人類在改變自己跟 AI 的關係,用一種他們自己可能都沒有意識到的速度。Anthropic 內部的使用數據也指向同一個方向:最難的任務上,Claude 的成功率翻了一倍,人類每次對話的平均介入次數從5.4降到3.3。AI 做得越好,人類管得越少,這兩條曲線之間撐開的空間就是 deployment overhang 的本體。
操控桿和三明治
使用者怎麼變化的?數據比直覺複雜。
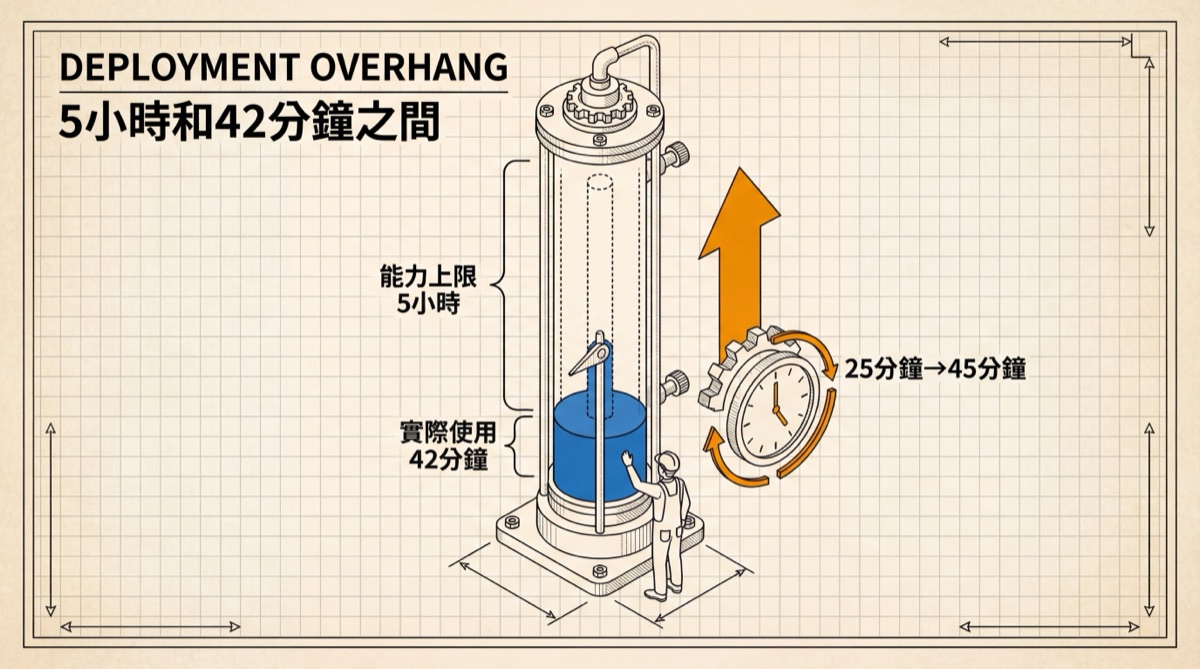
Claude Code 的新手,大概20%的 session 開着全自動模式。用過750次以上的熟手,超過40%。信任是慢慢長出來的,一次一次確認沒出事,下一次就少看一眼。到某個臨界點,確認本身變成了摩擦力,而摩擦力在效率的語境裡是負面詞。
同時,熟手打斷 AI 的頻率也漲了,從5%到9%。這不矛盾。新手是一步一步看着走,看到的東西多,需要攔的少。熟手是放開了跑,平時不管,但練出了一種嗅覺,知道什麼時候該探頭看一眼。像一個老司機,不再每秒鐘都盯着儀表板,但餘光掃到轉速不對的時候反應比新手快。知名 AI 工程師寶玉(@dotey)說得精準:強工具放大的是使用者之間的能力差距。老手鬆手是因為他知道什麼時候該收,新手鬆手是因為他不知道自己在鬆手。
AI 站在那裡等人類放繩,而人類正在一段一段地放。
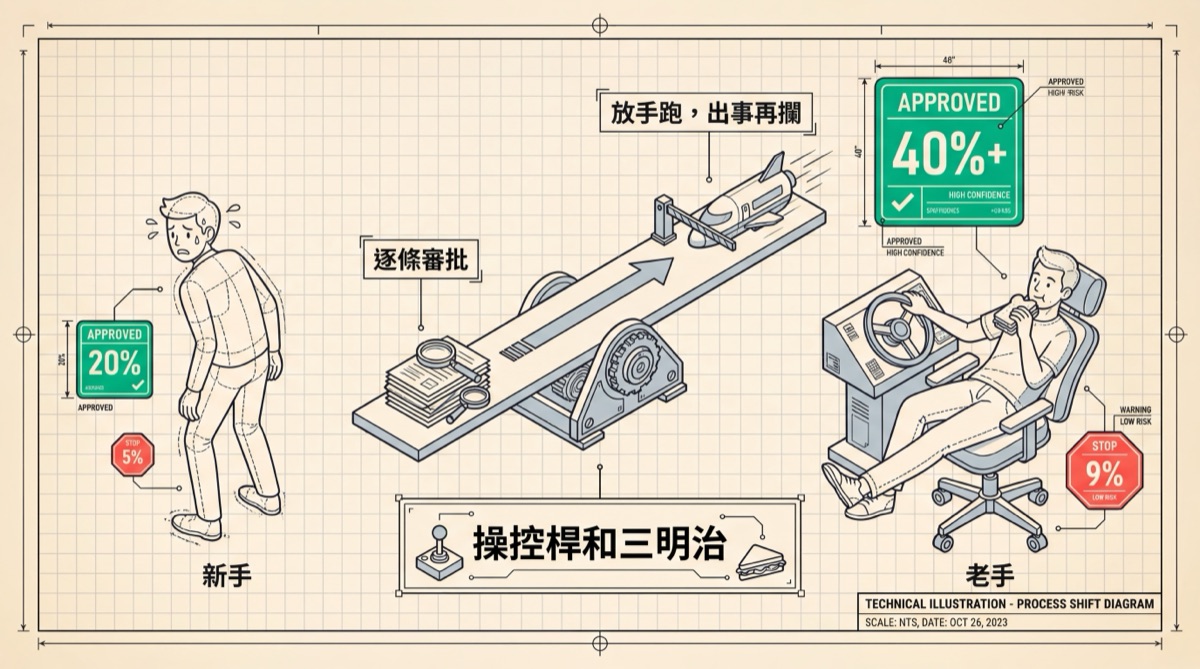
真正讓人發冷的數字在任務那一端。簡單操作(改一行代碼那種)有87%涉及人類參與。複雜任務(自動挖零日漏洞、從頭寫編譯器)只有67%。任務越重要,盯的人越少。邏輯很直覺:步驟多到一定程度,你根本沒辦法逐條審批,只能放。但「沒辦法逐條審批」和「不需要逐條審批」是兩碼事。前者是能力的局限,後者是安全的判斷。現實中兩者被混為一談了。
2009年6月,法航447從里約飛巴黎。大西洋上空,空速管結冰,自動駕駛斷開。飛行員要在幾秒內從「什麼都不用管」的狀態切入「全手動操控」。飛行紀錄器顯示他們拉高機頭,在飛機已經失速的情況下繼續爬升,三分多鐘後以每分鐘超過三千米的速度墜海。228人,零生還。調查報告的結論不是他們技術差,是他們太久沒有手動飛了。自動化養出來的信任,在系統失靈的那一刻變成了致命的真空。AI Agent 的用戶正在同一條跑道上加速。但飛行員好歹還有年度模擬器考核。用 AI 的人連個年檢都沒有。
一面很好看的鏡子
報告裡藏着一個讓人啞然的反轉。
最複雜的任務上,Claude 自己主動喊停、問人類「要不要確認一下」的頻率,是人類主動打斷它的兩倍以上。造出來的東西比使用它的人更小心。這到底是 AI 訓練得好,還是人類太隨便,答案可能兩個都是。
Anthropic 列出了一堆讓人安心的統計:80%的 tool call 有某種防護機制,73%有人類在迴路某處,0.8%是真正不可逆的操作。乍看之下像一面品質報告,質檢通過率很高。但品質報告只有在樣本分佈均勻的時候才有意義。現在的樣本嚴重偏科:軟件工程霸佔了 Agent 用量的將近50%。寫代碼、跑 debug、改配置,這些操作的風險基本等於零,寫錯了 revert 就好。這些低風險的量體把整個分佈拖向安全區。但報告同時指出,醫療、金融和網絡安全領域的 Agent 用量正在萌芽。在這些領域,寫錯一行不是 revert,是法律責任、財務損失或病人安全。等這些高風險場景的佔比從百分之幾漲到百分之幾十,今天的73%就會像一面擦得很亮但只照半邊臉的鏡子。
Anthropic 在報告裡承認了一件更根本的事:他們目前無法把公共 API 上獨立的請求組裝成完整的 Agent session。他們的客戶用 Claude 搭了什麼 Agent、串了什麼工作流、做了什麼操作,Anthropic 只看得到一塊一塊的碎片。整張拼圖是什麼樣子,他們跟你我一樣不知道。造引擎的人都不知道車開去了哪裡。你對監管基礎設施還有什麼期待?
回饋循環的靜音按鈕
這個系列前六篇講的是衝擊和分配:定價權崩塌、紅利失衡、自由職業的裸奔、SaaS 慣性的幻覺、保鏢被重新定價、效率果實的階級清洗。每一篇都有一群被撕裂的人,和一台正在撕裂他們的機器。
第七篇沒有受害者照片。一個工程師開了 auto-approve,省了三分鐘。隔天又開,又省了三分鐘。一個月後,不開反而覺得卡。半年後,他已經不記得有這個開關了。他的同事看到他這樣做,也開了。Slack 頻道裡有人分享了一套 prompt,配上 auto-approve 能把日常工作壓縮到一半。大家都用了。季度 review 的時候,經理看到效率翻倍,沒有問為什麼翻倍。下一季的 KPI 以翻倍後的基線重新設定。到這一步,誰想關掉 auto-approve 誰就是拖後腿的那個。回饋循環閉合了。「人類監督」這個環節沒有被任何人移除,它是在激勵結構裡慢慢蒸發的,跟歷史上每一個中間組織的消亡一樣:宗族、行會、工會,不是被明令禁止的,是變得不划算了,然後悄無聲息地空心化。等到真正出事需要它們的時候,位置空了。
Anthropic 報告的最後一段說得很克制:不應該強制要求人類審批每一個操作,那不切實際。真正重要的是人類處於「能有效監控和介入的位置」。這是學者的措辭。翻成直白話就是:這個位置,目前,不存在。需要從頭發明出來。而發明它的方法和標準,連寫這份報告的人都承認他們還在研究。
AI 時代真正的風險不是機器叛變。是每個人都在做局部最優的選擇,而這些選擇加在一起指向一個沒有人選擇的結局。韁繩不是被搶走的,是一厘米一厘米滑出去的。AI 站在那裡等人類放繩,而人類正在一段一段地放。當你終於低頭看手的時候,發現手是空的。

_(本文數據來源:Anthropic「Measuring AI Agent Autonomy in Practice」研究報告(2026-02-20)、METR「Measuring AI Ability to Complete Long Tasks」評估。如發現任何數據錯誤,歡迎指正。)_
_—Kinney 的異想世界_